AI画像はどうやって学習する?初心者でもわかる仕組みと技術の基本

「AIってどうやって絵を描いてるの?」
こう聞かれて、あなたはスッと答えられますか?
私も最初はまったく同じでした。
DALL·EやStable Diffusionで画像を生成してみても、「すごいな〜」で終わってしまって。
でもその“仕組み”をちゃんと理解していなかったんです。
あるとき、自分の描いたイラストを学習させようとしたら、専門用語の壁にブチ当たりました。
「CNN?GAN?特徴量抽出?…え、ちょっと待って?」
でも、そこで諦めずに仕組みから向き合ってみたら、プロンプトの設計力が格段に上がったんです。
結果、クライアントにも喜ばれる画像が安定して出せるようになりました。
この記事では、そんな私の実体験をもとに「AIが画像をどう学習し、生成しているのか?」を人間の視点でわかりやすく解説していきます。
今「なんか難しそう…」と感じているあなたにこそ、読んでもらえたらうれしいです。
記事の目次
AIはどうやって画像を「学習」するのか?
AIが画像を学習するって、一体どういうことでしょうか?
「データを読み込んでるだけでしょ?」
と思われがちですが、実はもっと奥深い仕組みがあります。
人間が絵を描くプロセスと、AIが画像を生成するプロセスには、意外な共通点があるんです。
たとえばあなたが「青空の下を走る犬」を描くとしますよね。
頭の中にある“イメージ”を、記憶の中の犬や空のパーツから呼び出して、構図を組み立てていくはずです。
AIも似たようなことをしています。
AIはまず、大量の画像とそれに対応する説明テキスト(キャプション)を学習します。
「この画像には何が写っていて、どんな特徴があるか?」という“関係性”をひたすら記憶していくわけです。
これを教師あり学習と呼びます。
そして次に、テキスト入力(=プロンプト)に対して、「その意味に近い画像」を思い出しながら再構成するんですね。
そのとき使われるのが「CNN(畳み込みニューラルネットワーク)」や「ベクトル変換」といった技術です。
これは画像の輪郭や色・質感といった**“特徴量”**を数値で表すためのしくみ。
さらに近年では、「GAN(敵対的生成ネットワーク)」や「ディフュージョンモデル」といった“生成専用”の技術も加わり、AIは“ただ似せる”だけでなく、“ゼロから創る”力を持ち始めました。
ここで大事なのは、AIは“画像そのもの”をコピーしているわけじゃないということ。
「画像に含まれる特徴やルール」を学習して、新しい画像を再構成しているんです。
つまり、AIは「青空」「犬」「走る」という概念をそれぞれベクトルで理解し、
それを組み合わせて“それらしく”見える画像をつくっている、というわけです。
この流れを知ると、
「ただのブラックボックス」だった画像生成のしくみが、
少し身近に感じられるんじゃないでしょうか?
画像学習の全体像:人間とAIの共通点
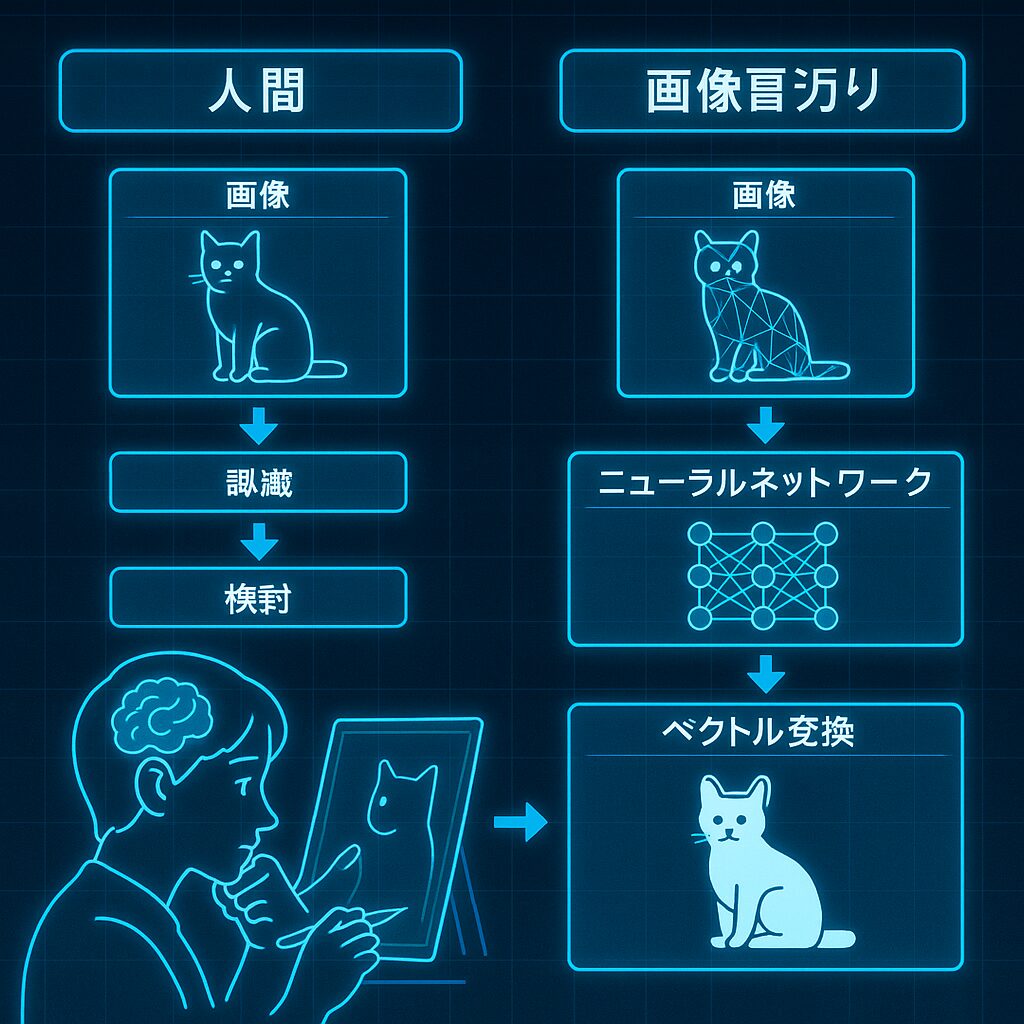
「AIって画像をどうやって覚えてるの?」
よくある疑問ですが、実は人間とけっこう似た仕組みなんです。
たとえばあなたが、見たことない動物の絵を描くとします。
完全にゼロから描くのは難しいですよね?
でも、「犬っぽいけど耳が長い」「体の模様は猫に近い」みたいに、
頭にある知識を組み合わせれば、それっぽく描ける。
AIも同じで、大量の画像と説明文を見て「これは猫っぽい」「これは夜空っぽい」と特徴を覚えていきます。
そのうえで、「こういう画像を作って」と指示されると、
学んだ特徴を組み合わせて“それらしい画像”を作るんです。
つまり、人間もAIも「見る → 覚える → 組み合わせる」という流れでアウトプットしている。
だから私はプロンプトを作るとき、“人間に説明するつもり”で書いてます。
たとえば「幻想的な空」じゃなくて、「紫色の雲」「やわらかい光がにじむ」など、具体的な言葉にすると精度が上がる。
AIは意外と人間っぽい。
だから、ちょっと“やさしく教えてあげる”くらいがちょうどいいんです。
主要技術①:CNNとは?】
「CNN」って聞くと、ニュースチャンネル?って思うかもしれませんが(笑)
ここで言うCNNは「畳み込みニューラルネットワーク(Convolutional Neural Network)」のこと。
画像をAIが“ちゃんと見て判断できるようにする”ための仕組みです。
ざっくり言うと、画像の中にある「特徴」を見つける技術です。
たとえば、犬の顔を見つけるとき、
耳の形とか、鼻の位置とか、毛並みの模様とか、
細かいパーツを順番に見ていくイメージ。
CNNはその“見ていく順番”がうまいんです。
しかも、「大きく見る」「細かく見る」を何層にも重ねることで、
画像の輪郭や質感、色のグラデーションまでしっかり掴めるようになる。
まるで、目がよくて観察力のある人みたいに。
この技術のおかげで、AIは「これは犬」「これは空」といった分類だけじゃなく、
「この部分は耳っぽい」「この模様は木に似てる」といった**特徴の“かたまり”**を理解できる。
私がプロンプト設計で意識してるのもここで、「この特徴が伝われば、CNNがしっかり拾ってくれる」って感覚で言葉を選んでいます。
つまりCNNは、画像をAIの“目”にしてくれる仕組み。
この“目”があるからこそ、AIは画像を学習できるんですね。
主要技術②:GANとディフュージョンの違い
AIが画像を「生成」するときに使われる代表的な技術が、GAN(ガン)とディフュージョンモデルです。
聞き慣れない名前ですが、ざっくりイメージできればOKです。
まずGAN(敵対的生成ネットワーク)から
これは「2人のAIがケンカしながら絵を仕上げていく」ような仕組み。
1人目(生成器)は画像を描きます。
2人目(識別器)は「これは本物?偽物?」とジャッジします。
生成器は「もっとリアルに見せてやる!」と改善を繰り返し、
識別器は「いや、これはまだ偽物!」と指摘し続ける。
このやり取りを何度も繰り返すことで、本物そっくりの画像が完成するわけです。
一方、ディフュージョンモデルは“逆再生”タイプ
最初にノイズ(ザラザラの砂嵐のような画像)を用意して、そこから少しずつ“ノイズを消して”いくことで画像を作っていきます。
これはいわば「何も見えない状態から、少しずつ絵を浮かび上がらせる」ような方法。
この手法はStable Diffusionなどで使われていて、より繊細で高解像度な画像を出しやすいという特徴があります。
ざっくりまとめるとこんな感じです。
| 技術 | 特徴 | 向いていること |
|---|---|---|
| GAN | AI同士で競い合いながら画像を進化させる | 写真っぽいリアルな画像生成 |
| ディフュージョン | ノイズを消して画像を再構築する | 高精度・高解像度な画像生成 |
私自身、GANの原理を知ったとき「なるほど、だから精度が上がるんだ」と納得しましたし、ディフュージョンを試したときは「なんでこんな細部まで描けるの?」と驚きました。
技術を知ると、プロンプトの設計も変わります。
仕組みを知った上で指示すれば、AIはちゃんと応えてくれますよ。
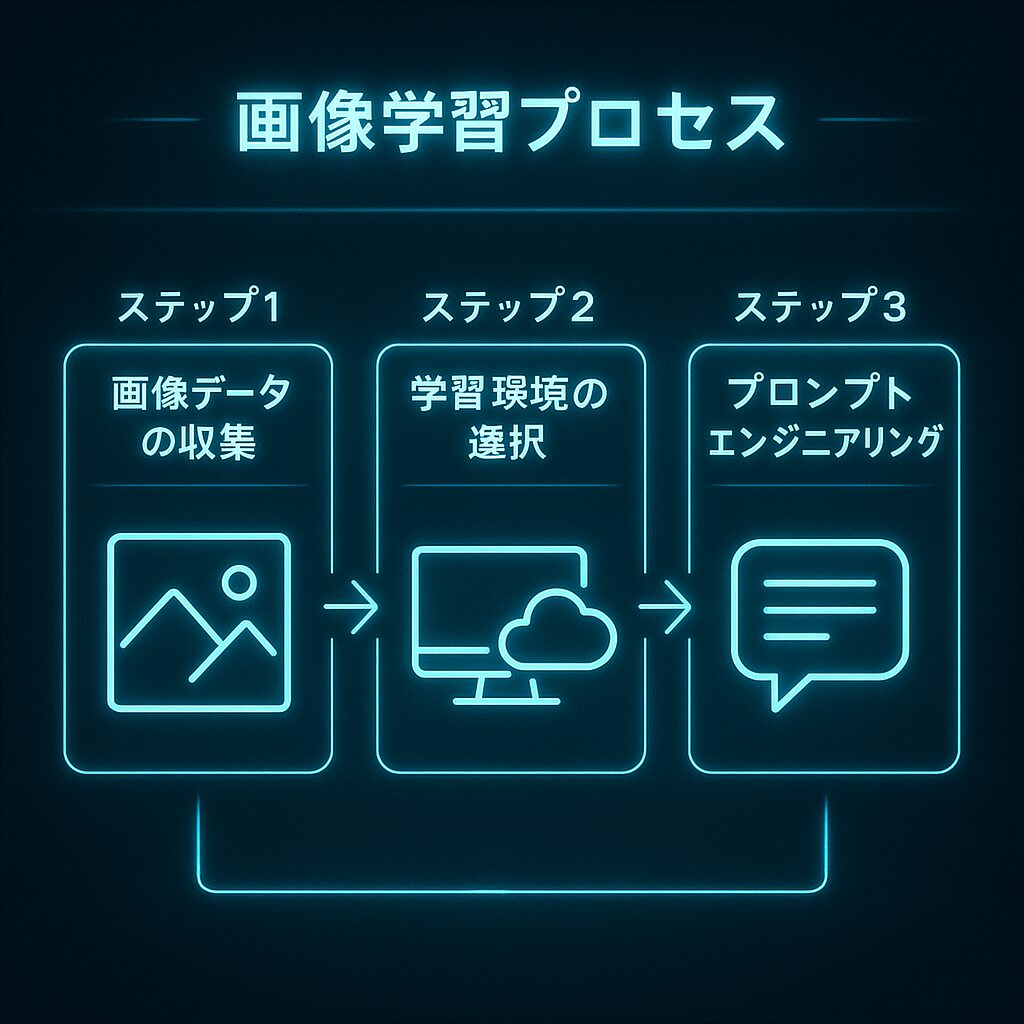
実際に画像を学習させるには?

仕組みがわかったら、次は**実際に“画像を学習させてみる”**ステップへ。
…とはいえ、最初は「え、どうやるの?」「何が必要?」ってなりますよね。
私も最初はまったく同じで、手順が分からず何度もつまずきました。
だから今回は、超シンプルな3ステップで整理します。
仕組みがわかったら、次は**実際に“画像を学習させてみる”**ステップへ。
…とはいえ、最初は「え、どうやるの?」「何が必要?」ってなりますよね。
私も最初はまったく同じで、手順が分からず何度もつまずきました。
だから今回は、超シンプルな3ステップで整理します。
ステップ①:画像データを集めて整理する
まず必要なのは「学習させたい画像」です。
・自分で描いたイラスト
・撮影した写真
・フリー素材(著作権クリアなもの)
など、“意味が明確な画像”を100枚〜数千枚ほど集めましょう。
それと同時に「これは犬」「これは夜空」などの説明(アノテーション)もセットで用意します。
→ AIが「何が写っているのか」を理解するために重要です。
ステップ②:学習環境を選ぶ・作る
次に必要なのが学習を実行する場所です。
選択肢は大きく3つあります。
| 環境 | 特徴 |
|---|---|
| ローカルPC(高性能GPU搭載) | 自由度が高い/構築がやや大変 |
| Google Colabなどのクラウド | 無料〜有料で使える/環境構築が楽 |
| スマホアプリ(簡易学習) | 手軽に体験できるが自由度は低い |
私はColabをよく使っています。
面倒な環境設定もテンプレで済むし、GPUも使えるのでかなり便利です。
ステップ③:プロンプトを調整しながら追加学習する
学習データを読み込んだあとは、プロンプトでどう表現するかが重要です。
たとえば、私の開発したプロンプト設計ではPinterest風の画像を生成するために「背景:白」「彩度:中」「構図:上半身のみ」といった具体的な特徴を文章化しています。
このように“どんな画像を出したいか”を明確に伝えることで、学習した内容がより正確に反映されるんです。
「自分でもできそうかも」と思えてきましたか?
この3ステップをベースにすれば、あなたの描いた絵や撮った写真をAIに学ばせて、オリジナル画像を作ることもできます。
難しく見えるAI学習、意外とやってみると楽しいですよ。
AI画像生成の“見えないリスク”にも目を向けよう
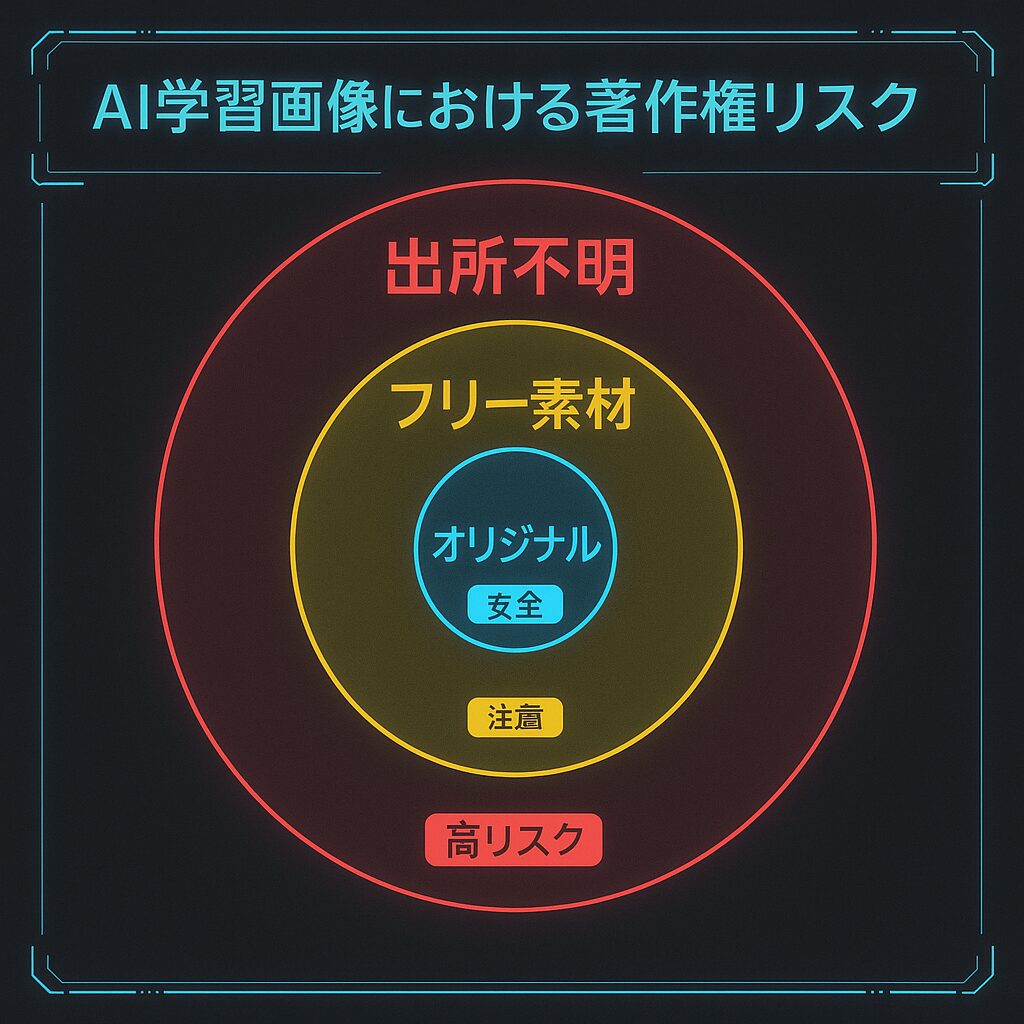
画像生成AIは便利で楽しい反面、**気をつけなければいけない“見えない落とし穴”**もあります。
実際に私が運用を始めたときも、思わぬトラブルやモヤモヤに直面しました。
特に注意しておきたいのが、以下の3つ。
- 学習データの偏りによるAIのクセ
- 使っていい画像・ダメな画像の線引き(著作権)
- 生成した画像の“権利”は誰のものか?
れらは知らずに使ってしまうと、後から炎上や削除依頼、信頼の低下といったリスクに繋がる可能性があります。
でも逆に言えば、最初から仕組みを理解して“使い方をコントロール”できれば、十分に回避できる問題でもあるんです。
この記事の後半では、それぞれのリスクについて具体的に紹介していきます。
安心してAI画像を活用していくためにも、テクニック”だけでなく“リスク管理”の視点も一緒に身につけていきましょう。
学習データの偏りによる影響
AIに画像を学習させるとき、**とても重要なのが「データの偏り」**です。
正直ここ、見落とされがちです。
私自身、最初に作ったモデルで「なんか似たような画像ばっかり出るな…」と違和感を覚えました。
理由はシンプル。使った画像が、白人男性ばかりだったからです。
AIはあくまで「見せられたもの」を学ぶので、もし“偏った画像データ”だけを与えれば、偏ったアウトプットしか返してきません。
つまり、
・女性が出てこない
・肌の色が同じ
・構図がワンパターン
…みたいな状態になります。
しかも厄介なのは、学習後に修正が難しいこと。
だからこそ、最初から意識して「性別・年齢・人種・背景の多様性」を入れておくことが大事です。
さらに、あなたが作るAI画像が“誰かの表現”に影響を与える可能性もあることを忘れないでください。
たとえばSNSで拡散されれば、「これは正しい表現なんだ」と無意識に刷り込まれるかもしれない。
だから私は、プロンプト設計だけでなく、学習データそのものの“バランス”にも目を向けるようにしています。
偏りは悪ではありません。でも「意図的にコントロールする」ことが、AIを扱ううえでとても大切です。
著作権と法的リスクについて
画像生成AIを使うときに、意外と盲点になるのが「著作権」の問題です。
私自身、最初は「自分でプロンプト打って作った画像なんだから、全部自分のものだよね?」と思ってました。
でも実は、それ、グレーなんです。
そもそも、AIは“既存の画像”を学んでいる
AIは完全にゼロから画像を生み出しているわけではなく、誰かが作った写真・イラスト・絵画などを学習素材にしています。
たとえば、学習データの中に「特定のアーティストの作品」が大量に含まれていた場合。
AIがその“作風”を真似て生成した画像には、オリジナリティの境界線があいまいになるリスクがあります。
これが「スタイルの盗用」として訴えられた事例も、海外ではすでに出ています。
フリー素材・自作画像を使うのが鉄則
だから私は、
・自分で描いたイラスト
・ライセンスが明確なフリー素材サイトの画像
・商用利用OKのデータセット
この3つに絞って学習させるようにしています。
「あとから消せばいいや」ではなく、最初から“使ってOKな画像”だけで学習させるのが一番安心です。
生成した画像の権利はどうなる?
これはサービスごとに違います。
たとえばStable DiffusionやDALL·Eでは、生成した画像の著作権を「利用者に帰属」としているところが多いです。
でも、商用利用・再配布・販売がOKかどうかは、必ず各サービスの利用規約を確認することをおすすめします。
「知らなかった」では済まされないのが、AIと著作権の世界。
せっかく作った作品だからこそ、安心して使える環境づくりを意識していきましょう。
まとめ:AI画像生成の仕組みを知れば、もっと自由に使える
画像生成AIって、最初はどうしても「難しそう」「よくわからない」って感じますよね。
私もそうでした。専門用語がズラッと並ぶだけで、もう心が折れそうになる。
でも、仕組みを“ざっくり”でも理解してからは、見える景色がまったく変わりました。
「AIは人間と同じように“見て覚える”んだ」
「プロンプト次第で、精度も雰囲気も大きく変わるんだ」
そう気づいてから、私はAIと“対話する感覚”で画像づくりを楽しめるようになったんです。
あなたがこの記事で得た知識をもとに、
「まずは1枚、自分の画像を学習させてみようかな」って思えたなら最高です。
最初から完璧じゃなくてOKです。
ちょっとだけ仕組みに踏み込めば、AIはぐっと身近になります。
仕組みがわかると、本当の意味で使いこなせるようになる。
次は、あなたの手で試してみませんか?
私がこの記事を書いたよ!
ariko WEBマーケAIエンジニア
プロモーターとしてオンラインで計20億以上の売上に貢献。Udemy4.2講師。WEBマーケティングやセールスライティングを行い自動化も経験あり、ジェネラリストとして活動していたがAIとの出会いですべてをAI化をすることに成功をし現在はAIの専門家として活動している。
関連記事関連性が高いおすすめ記事


- 2025年5月31日
AIロゴ作成はここまで進化!初心者でもプロ級に仕上がる実践ガイド
「AIでロゴを作ってみたけど、なんかピンとこない…」そんな風に感じたこと、ありませんか?もちろん、私も最初はそう……


- 2025年5月28日
自然すぎて驚く!AI画像合成の無料ツール5選&初心者向けガイド
「え、これ本当にAIで合成したの?」思わずそんな声が出るほど、最近のAI画像合成ってめちゃくちゃ自然なんですよね。……